The Method
The methodology behind frequency analysis relies on the fact that in any language, each letter has its own personality. The most obvious trait that letters have is the frequency with which they appear in a language. Clearly in English the letter "Z" appears far less frequently than, say, "A". In times gone by, if you wanted to find out the frequencies of letters within a language, you had to find a large piece of text and count each frequency. Now, however, we have computers that can do the hard work for us. But in fact, we don't even need to do this step, as for most languages there are databases of the letter frequencies, which have been calculated by looking at millions of texts, and are thus very highly accurate.
The methodology behind frequency analysis relies on the fact that in any language, each letter has its own personality. The most obvious trait that letters have is the frequency with which they appear in a language. Clearly in English the letter "Z" appears far less frequently than, say, "A". In times gone by, if you wanted to find out the frequencies of letters within a language, you had to find a large piece of text and count each frequency. Now, however, we have computers that can do the hard work for us. But in fact, we don't even need to do this step, as for most languages there are databases of the letter frequencies, which have been calculated by looking at millions of texts, and are thus very highly accurate.
From these databases
we find that "E" is the most common letter in English, appearing about
12% of the time (that is just over one in ten letters is an "E"). The
next most common letter is "T" at 9%. The full frequency list is given
by the graph below.
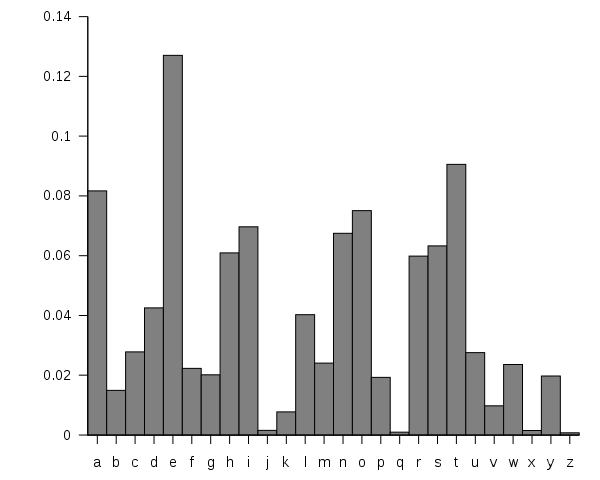
This chart shows the
frequencies with which each letter appears in the English language. It
clearly shows that "e" is the most common, followed by a small cluster
of other common letters.
|
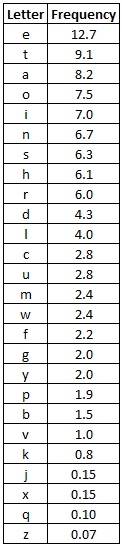
The frequencies of letters appearing in the English language, in order from most common to least.
|
We can use this
information to help us break a code given by a Monoalphabetic
Substitution Cipher. This works because, if "e" has been encrypted to
"X", then every "X" was an "e". Hence, the most common letter in the
ciphertext should be "X".
Thus, if we intercept
a message, and the most common letter is "P", we can guess that "P" was
used to encrypt "e", and thus replace all the "P"'s with "e". Of
course, not every text has exactly the same frequency, and as seen
above, "t" and "a" have high frequencies too, so it could be that "P"
was one of those. However, it is unlikely to be "z" as this is rare in
the English Language. By repeating this process we can make good
progress in breaking a message.
If we were to just
put all the letters in order, and replace them as in the frequencies, it
would likely produce jibberish. The codebreaker has to use other
"personality traits" of the letters to decrypt the message. This may
include looking at common pairs of letters (or digraphs): there aren't
many 2 letter words; there are only a few letters which appear as
doubles (SS, EE, TT, OO and FF being the most common). There are only
two sensical words made of a single letter in English. Other common
words also start to appear as you make some substitutions. For example
"tKe" might appear frequently after making substitutions for "t" and
"e". This is very likely to be "the", a very common word in English. There is a list of useful statistics for the english language available here.
The process of
frequency analysis uses various subtle properties of the language, and
for this reason, it is near impossible to have a computer do all the
work. Inevitably, an element of human input is necessary in this process
to make educated decisions about which letters to substitute.http://crypto.interactive-maths.com/frequency-analysis-breaking-the-code.html


No comments:
Post a Comment